最近做的一些毕设工作
最近一直忙于做毕设,学了很多,但是发现自己的知识储备还是不太够,毕竟深度学习这一方面确实涉及的范围太广了,真正实现起来还是需要耗费大量时间
真正端到端的识别网络:
masktextspotterv3
没有使用,数据集太少了,使用起来会很差,暂时不考虑
百度飞桨平台ppocr 教学指导视频
https://aistudio.baidu.com/aistudio/education/group/info/25207
目标检测部分
目标检测看了很多,开始想用corner做的,但是后来看到了这个DBnet,感觉好像还不错,因为速度快,同时检测的难度也不会特别高,因此最终决定使用了DB
在使用github源码编译时发现编译失败,windows平台编译失败,需要下载vs的buildtool,下载之后添加了路径,之后报错AT_CHECK 未定义,查看c++源码发现AT_CKECK在源码中并没有定义,查阅资料发现将TORCH中的TORCH_CHECK取别名def为AT_CHECK即可
然而因为官方库实现较为复杂,代码可读性不高,因此参考了另一个库
https://github.com/WenmuZhou/DBNet.pytorch
该库的实现可读性更高,且支持python使用
在对训练好的模型进行测试时,发现1核2GB内存的腾讯云服务器在使用DBNET判断单张图片时,耗费的时间接近3.5S,时间太长了,因此对infer代码进行了分析:
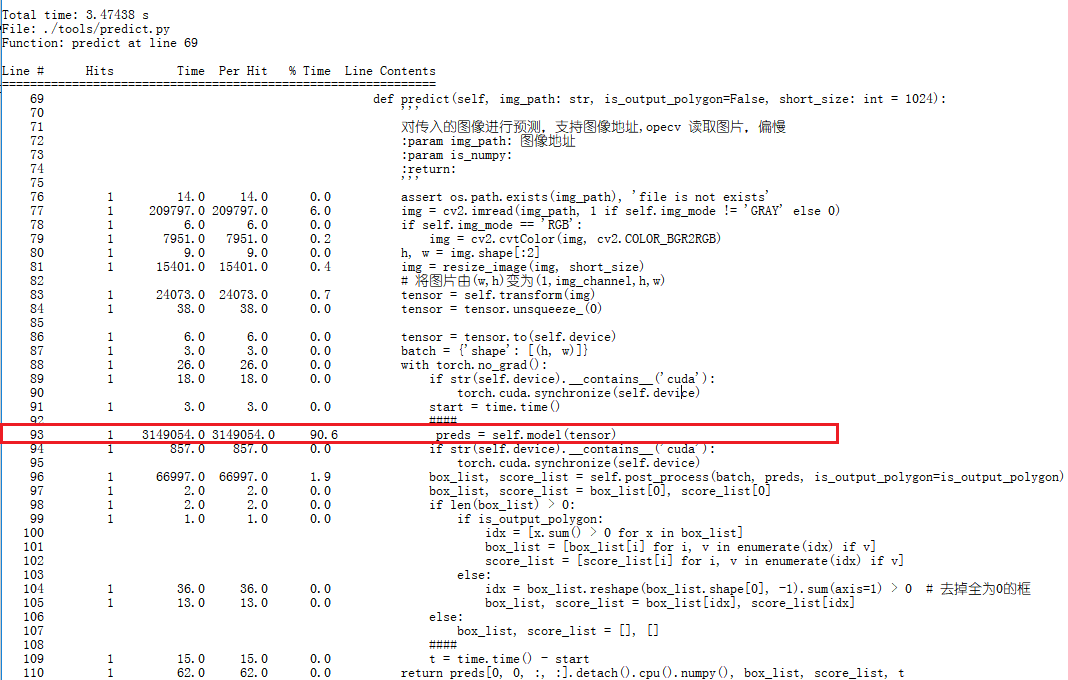
原先以为是因为opencv读取图像的效率低导致的,结果发现占大头的还是网络,网络总参数为1.85M,但是里面的计算量很高,
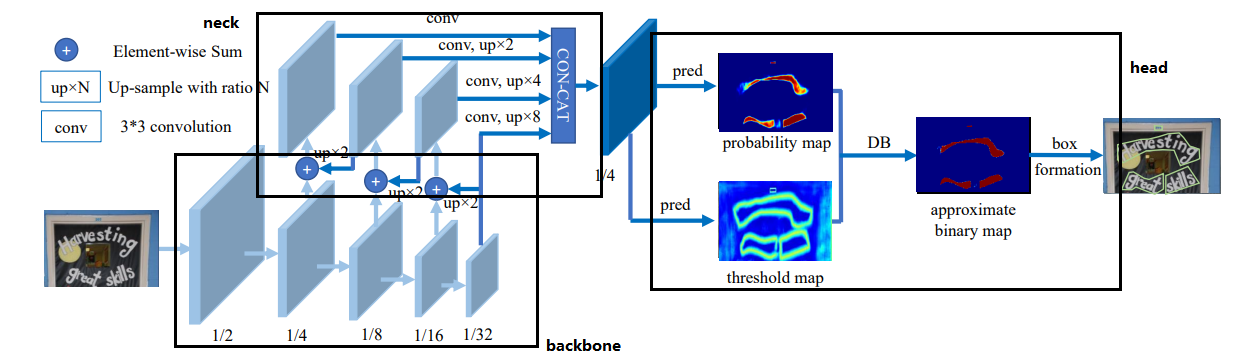
DBNet的网络可总体分为3部分,backbone、neck、head
backbone是特征提取网络,可用resnet18、resnet50、mobilenet等实现,neck则是特征金字塔结构的网络,而最后的head则是要先用将1/4的feature map 复原到完整的大小,然后通过进一步处理得到threshhold map和probability map(bitmap),最后将两张图片结合得到approximate binary map,需要注意的是,在实际推理期间,并不需要生成approximate binary map和threshhold map,这两个map都是为loss服务的,所以在infer时,只需要生成概率图bitmap即可,这也是DBNet速度快的原因之一。
https://www.bilibili.com/video/BV1xf4y1p7Gf?p=2
使用了ICDAR2015的数据先训练模型,然后再以该预训练模型用发票数据集进行训练
发票数据集中数据标注也不是特别规范,
DBNet训练结果:
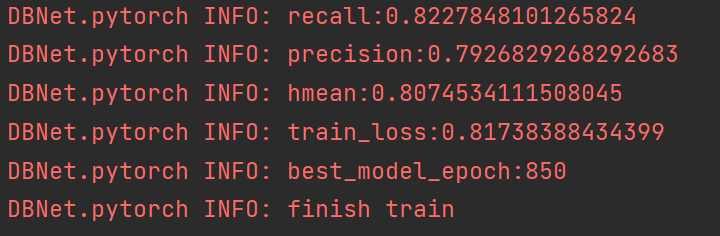
DBNET FPN结构中用的卷积是Deformable conv
在进行推理时,使用了直方图均衡化对图像进行处理
这是原图,可以看到这张车票中的打印文字颜色部分很淡,因此我在模型推理前做了一下直方图均衡化,看看图像增强后的推理结果,但是效果似乎并不好。
文字识别部分
思路是先进行文本检测,再进行文本识别。之所以没有进行端到端的检测识别,是因为考虑到文本的识别比较依赖与数据集的质量,如果进行完全的端到端的识别,在数据集数量不够的情况下,效果很难提升。虽然模型大小可能会减少很多,但是精度可能会大打折扣。
有个很好的办法可以将模型大小再次减少不少,就是将输出的类别减少,其实发票数据集所需的文字alphabet不需要太多,可能只需要几百个就可以了,用的最多的就是一些大小写字母、数字和标点符号,以及百来个版面上用的文字信息,这样的话,最后进行linear连接的时候,参数的数量能够减少3M左右。
目前模型概况:
CRNN mobilenet V3 + RNN
===================================================================
Layer (type:depth-idx) Output Shape Param #=====================================================================
├─CNN: 1-1 [-1, 512, 1, 40] –
| └─Conv2d: 2-1 [-1, 16, 16, 80] 144
| └─BatchNorm2d: 2-2 [-1, 16, 16, 80] 32
| └─hswish: 2-3 [-1, 16, 16, 80] –
| └─Sequential: 2-4 [-1, 160, 1, 40] –
| | └─Block: 3-1 [-1, 16, 16, 80] 752
| | └─Block: 3-2 [-1, 24, 8, 40] 3,440
| | └─Block: 3-3 [-1, 24, 8, 40] 4,440
| | └─Block: 3-4 [-1, 40, 4, 40] 7,676
| | └─Block: 3-5 [-1, 40, 4, 40] 14,060
| | └─Block: 3-6 [-1, 40, 4, 40] 14,060
| | └─Block: 3-7 [-1, 80, 2, 40] 32,080
| | └─Block: 3-8 [-1, 80, 2, 40] 34,760
| | └─Block: 3-9 [-1, 80, 2, 40] 31,992
| | └─Block: 3-10 [-1, 80, 2, 40] 31,992
| | └─Block: 3-11 [-1, 112, 2, 40] 114,360
| | └─Block: 3-12 [-1, 112, 2, 40] 166,040
| | └─Block: 3-13 [-1, 160, 2, 40] 234,032
| | └─Block: 3-14 [-1, 160, 1, 40] 248,048
| | └─Block: 3-15 [-1, 160, 1, 40] 348,560
| └─Conv2d: 2-5 [-1, 512, 1, 40] 81,920
| └─BatchNorm2d: 2-6 [-1, 512, 1, 40] 1,024
| └─hswish: 2-7 [-1, 512, 1, 40] –
├─Sequential: 1-2 [-1, 2, 5990] –
| └─RNN: 2-8 [-1, 2, 5990] –
| | └─LSTM: 3-16 [-1, 2, 512] 1,576,960
| | └─Linear: 3-17 [-1, 512] 262,656
| | └─LSTM: 3-18 [-1, 2, 512] 1,576,960
| | └─Linear: 3-19 [-1, 5990] 3,072,870=======================================================
Total params: 7,858,858
Trainable params: 7,858,858
Non-trainable params: 0
Total mult-adds (M): 110.31========================================================
Input size (MB): 0.02
Forward/backward pass size (MB): 16.30
Params size (MB): 29.98
Estimated Total Size (MB): 46.29========================================================
识别精度不高,可以考虑关键词匹配,例如识别出
环境:
环境需求:
- OpenCV-python
- PyTorch 1.8.0
- lmdb(一个基于内存映射的key-value数据库,用于打包存放训练或是测试数据)
文字检测部分考虑使用DB Net,DBNet检测速度快,先进性测试看看效果
网络:
网络为了尽量将模型参数减少,将crnn中的cnn从原先的VGG-16改成了mobilenetv3,网络复杂度减少了许多,从生成的pytorch模型pth文件大小就可以看出来。
训练:
数据:
数据集采用的是2021年ccf出租车发票识别比赛的数据集
里面分为两train和test两个部分,train里面为labelme格式的json文件和与其对应的原图,图像为整张地发票,json文件中标注出了图像中的文本位置以及其文本标签。
使用的alphabet 把其中的全角冒号:删除,用半角冒号:,括号也是同理,
test中的图像为截取出来的文本的图片,没有标签。
需要对crnn中的数据进行处理
因此写了一个python脚本将检测文本的位置信息以及文本内容解析出来,通过cv2裁剪出来并保存。将标签提取到label文件中,并附上对应的图像路径。
之后便得到了一个存放图片的文件夹以及一个存放对应图像路径以及标签的文件,编写脚本,将标签与图像读取出来,以kv方式存放,label为k,图像的数据为v。在写入时,出现了一个问题
TypeError: Won't implicitly convert Unicode to bytes; use .encode()
lmdb数据库不会自动将将Unicode格式编码,因此存放数据时,必须手动将文件进行编码,否则将会一直报错。其中key和value都需要进行编码。
一开始从原有的数据集进行训练,数据量比较小,一共3400张图片左右,训练之后发现准确率上升到50左右就已经到顶了,个人分析,首先就是数据集量太少了,其次是因为这里的数据集质量比较低,这些图片都是从原先整张图像中裁剪出来的,而发票中的字又很小,可能原先一张600×800像素的发票图片,裁剪出来的文字大小只有20×23,因此这里虽然又3400多张图片但是实际像素勉强合格的图片实际上只有2000多张(横向的width大于60的情况下)。
这50多的准确率实在是太低,因此采用了预训练模型的方法,先用通用的文字识别数据集进行训练,训练到一定成都之后再将数据集切换到发票数据集,这么做了之后识别的准确率提高到了60左右,但是仍然有点问题。后面去询问导师,导师说可以考虑对数据集进行扩充,采用数据增广的方式。我将原先的图像随机进行了一些透视变换、高斯模糊等处理,这样之后数据集扩充了2倍,一共来到了8000左右,经过这样几个处理,识别的准确率到达了70左右之后就不再继续上升了。
考虑到发票识别中的文字不会出现很多,因此我尝试将原先数据集大量增广,将数据扩大到了原来的50倍,做了一些透视变换之后感觉也差不多,先训练着试试吧
之后的训练都在导师提供的服务器上进行了,我尝试将像素小于80的crop图片全给过滤了,之后对模型进行训练,结果acc低了很多,只到了60就封顶了,看来这样较低的crop图片也需加入到训练数据中,至今,数据集数据量太少仍是个大问题
出租汽车发票识别具有其特殊性,总体来说可以分为两部分:版面部分和数据部分,其中版面部分是固定的,而数据部分是不定的,其中的难点就是图形的干扰,发票中存在许多印章,印章很有可能会将数据覆盖,增加了识别的不确定性,同时数据部分和版面部分不一定完全对正,有可能文字部分的数据会有偏移,严重的情况下会出现文字部分与版面重叠的情况,这种情况下,人眼也难以识别,很有可能会导致识别出现问题。
遇到的问题
使用gpu训练,torch版本使用了1.10.1,似乎不支持cuda,改成1.8之后可以使用gpu进行训练了
在服务器上使用cpu进行训练时发现数据集太大,导致无法解压,查看磁盘空间df -h,磁盘空间还够,经检查发现是索引节点不够了,df -i,文件中全是corp之后的图片,一共360多万张。转到windows,使用windows准备训练数据集,发现效率低下,全部的数据需要4小时左右才能写入数据库。
使用lmdb创建数据集进行使用时,首先要开辟一块lmdb环境,需要用到lmdb.open()这个函数,里面有个mapsize参数,就是开辟空间的大小,windows与linux下这两个参数会有不同
开始的时候用的是linux,linux下开辟了一个1T的空间,
env = lmdb.open(outputPath, map_size=1099511627776)
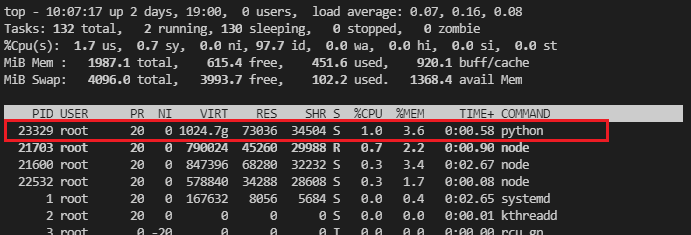
可以看到这里是linux中VIRT增加到了1T,也就是程序申请了1T的虚拟内存,但是我这台机子是腾讯云学生机,磁盘也就60G,在linux系统下,lmdb申请的空间大小并不会实际的在系统中开辟,在程序执行结束之后,查看数据库文件,发现大小也并没有1T,占用空间约为未打包的数据集的大小。
在windows则显得不同,在将同一段代码放到windows中运行时,程序却报错了,
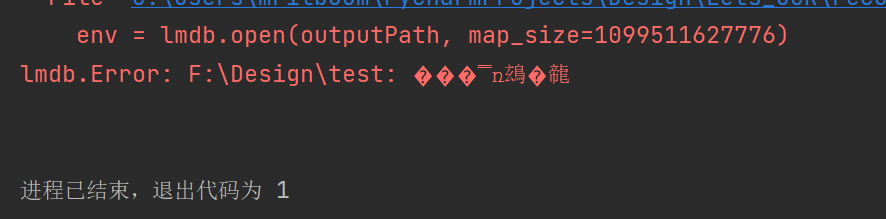
一堆乱码,后面费了很大的劲查询资料才发现是因为系统空间不足了,开辟1T的空间,但是系统磁盘不够,于是报错,于是我就调小点,调了大概70g左右,这个果然奏效了,然后等程序运行结束一看,生成的数据库文件竟然真的足足70G,我原以为这个只是开辟了一个临时空间,在运行结束后会将资源释放,结果并不是我想的那样。在windows的情况下,输入的mapsize大小就是最后生成数据库文件的大小,因此在windows下,mapsize需要特别注意的考虑一下,不然之后处理起来会很麻烦。