Oracle SQL高级编程阅读笔记
Oracle SQL高级编程阅读笔记
第一章 SQL核心
1.3 SQL * Plus
回顾、熟悉命令、可创建一个login.sql文件,使得每次打开SQL * Plus 时提前设置好相关的SQL * Plus环境变量
相关的执行命令方式:使用@或者START来执行.sql后缀的文件,使用/来重复执行上一条执行的语句
1.4 5个核心的SQL语句
-
SELECT
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT 列表(
SELECT a,b,c,(SELECT a1,b1,from table1),d,e FROM table) - ORDER BY
-
INSERT
- 单表插入
- 多表插入
-
UPDATE
-
DELETE
-
MERGE(合并,有则更新,无则插入)
第二章 SQL执行
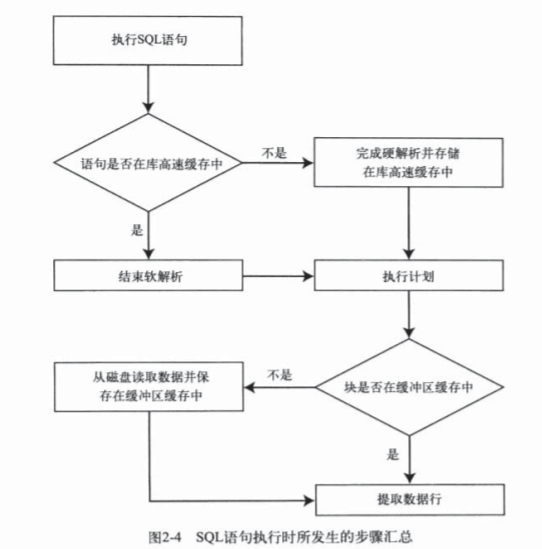
2.1——2.5 ORACLE 的CACHE机制
-
共享池——执行过的语句缓存在共享池中,采用LRU算法更新缓存
-
库高速缓存
-
软解析(直接使用cache中的数据,执行速度快)
-
硬解析(需要生成执行计划,速度慢)
-
-
相同语句(ORACLE直接对语句进行hash计算,如果语句出现任何变化即视为语句不同,即使只改变了语句大小写)
- 使用绑定变量可减少硬解析,加快执行速度
2.6查询转换
ORACLE可能会将一些子查询进行转换,如
1 | select * from employees where department_id in (select department_id from departments) |
可能会被转换为
1 | select e.* from employees e,departments d where e.department_id = d.department_id |
这里的结果集并不会有改变,但是第二局的解析执行速度会更加高效
2.7 -2.13一些优化解析执行速度的办法
主要列举了视图合并、子查询解嵌套、谓语前推、使用物化视图进行查询重写等优化解析的方式,这里一大部分全都在介绍硬解析中对于执行方案的优化与选择,最后确定出执行计划。
第三章 访问和联结方法
访问方法
比较多的经验法则(ROT,Rule Of Thumb)提到一个判断是否要使用全扫描访问的依据——查询将取出表中多少的数据行。如果多于百分之多少,就应该用全扫描,这个说法有依据,但凡事总有例外,大部分情况下这个法则是可行的。
-
全扫描访问
下面给出一段代码,在即使查询量只有所有数据的1%时全扫描也更占优势
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16create table t1 as
select trunc((rownum-1)/100) id, -- trunc函数将数字取整
rpad(rownum,100) t_pad -- rpad函数填充作用
from dba_source
where rownum <= 10000;
create index t1_dix1 on t1(id);
exec dbms_stats.gather_table_stats(user,'t1',method_opt=>'FOR ALL COLUMNS SIZE 1',cascade=>TRUE); -- 分析记录
create table t2 as
select mod(rownum,100) id,
rpad(rownum,100) t_pad
from dba_source
where rownum <= 10000;
create index t2_dix1 on t2(id);
exec dbms_stats.gather_table_stats(user,'t2',method_opt=>'FOR ALL COLUMNS SIZE 1',cascade=>TRUE);对于两张表的数据而言,其内容是一样的,但是其数据分布不同,
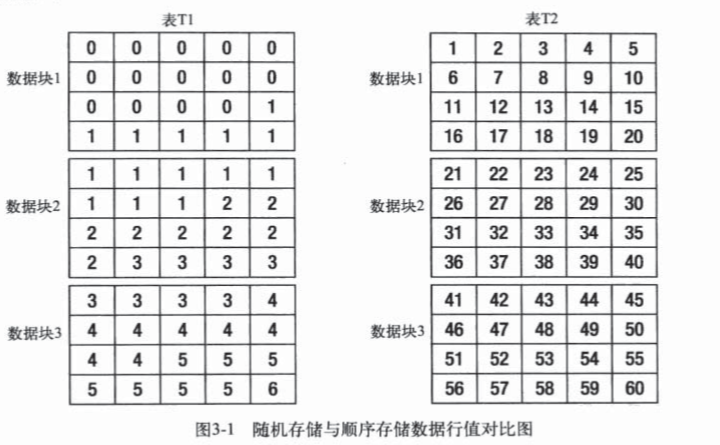
其中T1可以看成随机存储,T2可以看成顺序存储。全表扫描的话,只需要访问连续的几个数据块即可取得查询所需的数据,如果使用索引访问的话,就需要先查找索引,然后再找到rowid,以此定位到记录,所花的时间可能比全表扫描更长。
全扫描是否高效取决于舍弃的数据块与所访问的数据块,这两者增加时,全表扫描效率会降低,如果数据很多的时候,上述情况下,索引可能会更有效.
-
高水位线(HWM),理解为历史最高水位线会更好,它一般只增不减,
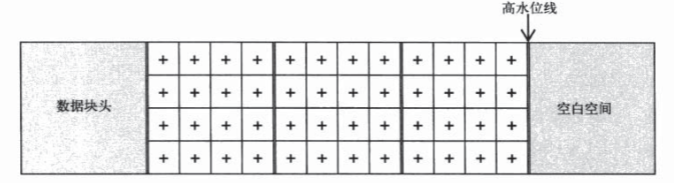
在经过一些数据变动后
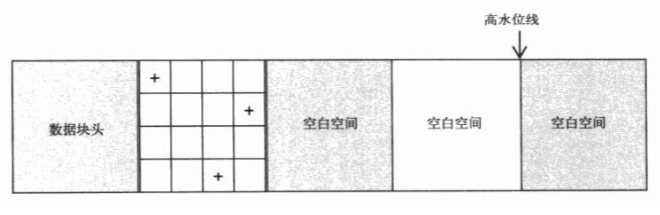
HWM是全表扫描的尽头,全表扫描总是从数据存储开始的点扫描到高水位线为止(这里暂时不理解为什么全表扫描要用这个参数,用当前水位线不是更好?这个HWM参数可能会导致数据查询时间大大增加),即使在之后数据有了删改,甚至只剩下一条数据,进行一次全表扫描仍需扫描到HWM为止。
-
-
索引扫描访问
索引扫描访问就像从书的目录中找出确定的几页,索引中的条目记录了主键的值和该值所在条目的地址,只要能够找到该键值,就能够很快的定位到该记录。索引默认按照B-树结构构建。
-
索引唯一扫描
当要使用unique或者主键的列作为条件时,就会使用索引唯一扫描
-
索引范围扫描
当返回数据可能不止一条时采用的方法,如使用了
<,>,>=等运算符 -
索引跳跃扫描
当谓语中包含位于索引中非引导列上的条件,并且引导列的值是唯一的时候会选择索引跳跃扫描。比如在一张索引为(gender,employee_id)的索引表中,
1
select * from employee where employee_id = 100;
此时就会采用索引跳跃扫描,看起来似乎跳过了前导列,直接对非前导列进行索引。上面的语句等效于
1
2
3select * from employee where gender = 'F' and employee_id = 100
union all
select * from employee where gender = 'M' and employee_id = 100;如果前导列中的分类太多(比如id为前导列),则不适合采用该方法
-
索引全扫描
有多种情况下都将选择索引全扫描,包括:当没有谓语但是所需获取列的列表可以通过其中一列的索引来获得,谓语中包含一个位于索引中非引导列上的条件,或者数据可以通过一个排过序的索引来获取并且会省去单独的排序步骤。(如
where name like "A%") -
索引快速全扫描
-
to be continue···