cx_Oracle操作Oracle数据库(二):代码篇
上一篇讲了cx_Oracle的安装以及相关的环境配置,本篇就来讲讲cx_Oracle这个模块的具体使用方法.
本文只介绍基本的一些数据库最基本的操作方法,不涉及到连结池、存储过程等操作
详细信息请参阅cx_Oracle官方文档
cx_Oracle一些对象的介绍
在成功连接数据库之后
在连接上数据库之后,cx_Oracle会返回一个Connection对象,该对象用的比较多的就是Connection.cursor()和Connection.close()了,前者是用来返回一个新的cursor 对象,我们进行的CRUD等大部分的操作都要用到cursor 对象来进行操作.后者则是关闭连接的操作,每次执行完程序后,都需要将连接关闭.
开始前的几个小建议
-
建立完数据库连接之后,尽量使用try——finally语句,避免因为程序出错而导致数据库连接未被正常关闭的现象的出现.
1
2
3
4
5
6conn = cx_Oracle.connect(DB)
try:
... # your codes
...
finally:
conn.close()这样一来,即使程序运行出错,最终也会关闭连接.
-
使用cursor游标时也要注意,需要手动关闭游标,不过为了方便,一般有需要到时可以使用with…as…的方法来进行调用,下面的这段代码能够确保一旦代码块完成,游标就会被回收关闭.
1
2
3with conn.cursor() as cur:
... # cursor operation
...
使用cx_Oracle
使用使用cx_Oracle进行查询
执行完对应sql语句后,游标可以通过按行进行迭代来获取所要查询的数据.
1 | with conn.cursor() as cur: |
同时也可以通过游标对象的fetch()方法来获取数据:
1 | with conn.cursor() as cur: |
这个方法首先通过游标cursor.execute()执行sql语句,之后通过cursor 的fetch方法来获取结果,通过打印输出可以看出执行语句获取的结果是以tuple元组的方式返回的,取到数据后就可以进行其他的操作了,而cur也随着代码执行结束自动销毁了.
除了用cursor.fetchone()方法之外,还可以用cursor.fetchall()``cursor.fetchmany(num_rows)方法来获取对应行数的数据.
如果返回的数据不止一条,数据则会以列表的方式返回,列表中的每一条数据都是一个元组,每个元组表示查询到的一行数据,如
1 | [("LiMing",12,1),("LiHu",13,1),("XiaoHong",12,0),("XiaoHui",12,0)] |
通过上述方法就能获取到我们执行数据库操作后查询到的结果了.
使用cx_Oracle进行其他操作(DML、DDL、DCL)
进行其他操作一般不需要处理返回结果集,用到的执行函数也是execute(),因此直接编写sql语句再调用execute()方法执行即可.
但是有一点需要特别注意,当cur.execute()执行一条 SQL 语句的同时会启动或继续一个事务.默认情况下,cx_Oracle 不会将此事务提交到数据库.方法conn.commit()和conn.rollback()方法可用于显式提交或回滚事务:
1 | cursor.execute("insert ... into ... values ...) |
数据库连接conn关闭时,任何未被提交的事务都会被回滚.
使用绑定变量(Bind Variables)
因为工作中需要对数据进行批量写入,我就进行了python中字符串format的用法对sql语句进行修改:
1 | sql = f""" |
执行也没有问题,但是在我一次查看文档时发现了一段话
Never concatenate or interpolate user data into SQL statements:
1 | did = 280 |
文档中说到千万不要直接用格式化字符串的方式提交sql命令,理由很简单,因为这样会存在sql注入的问题,把整句sql的语句交给用户来定义肯定是不理性的,之后看了一下文档,解决方法并不复杂,cx_Oracle提供了一个预编译传参的手段,将sql语句的命令预先编译,之后再将参数传入,以此来避免恶意的sql注入问题,我们可以通过cur.execute(sql,bind_params)这条命令来代替之前不安全的方法,bind_params是一个参数列表,比如之前的插入语句就可以修改为这样:
1 | sql = """ |
绑定变量方式可以按照位置、名称、类型等绑定,详细内容参阅Using Bind Variables.
数据批处理
cx_Oracle为提供了数据批量写入或更新的功能,使得sql语句只用编译一次即可,每次只需更改变量即可,适用于大批量的数据写入或更新的情况.下表将用于示例:
1 | create table CLASSROOM |
将下面6条数据数据一次性插入到数据库中,代码如下:
1 | data = [ |
该方法executemany()一次就可以将这批数据写入数据库,避免了5次往返写入,在大批量的数据上效果显著.
使用批处理时需要注意的一个问题
在我做解析excel文件时,想要进一步提高数据库写入速度,我就想用executemany()的批处理来优化,将读取到的每一行以append()的方式放入一个列表中,然后最终通过executemany()来一步完成,但是中间却报错了
1 | TypeError: expecting number |
这一看,显然是数据格式不对了,但是之前用execute()执行的时候从来没有出错,在仔细分析后,我找到了造成问题的原因,下图是我之前读取数据的excel原表(数据已做更改)
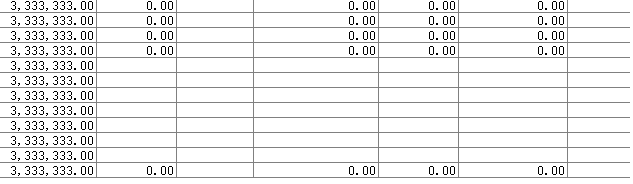
其中中间的几行数据并没有信息,在excel读取数据的时候会把空格读取成""
还是以之前的CLASSROOM 表为例,excel表如下:
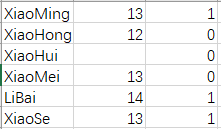
python从excel中读取到的数据如下:
1 | data = [ |
可以看到第4行中XiaoHui她的年龄数据因为缺失变成了"",与其它的数字类型不同,因此才造成的错误.而后我又尝试将插入的数据改成:
1 | data = [ |
使得第一行数据缺失,而后报错内容为
1 | TypeError: expecting string or bytes object |
至此,我也算是知道了这个报错的出现以及之前按条插入数据时没有出现错误的原因了
在执行execute()命令时,程序会自动按照输入的数据来编译出一条sql命令以适应数据库的表,之前每一次执行都会单独编译一条sql语句,例如输入了 ['XiaoHong',12.0,0.0],这一行数据,程序就会将对应的string,float,float转化成数据库中的所需求的string,int,int这样的格式,在下一轮迭代中,程序读取到了string,string,float,那么又会产生一个从string,string,float到string,int,int这样的映射以支持不同数据类型的输入.
然而在执行executemany()命令时,sql命令只会编译一次,所以它只能支持一组数据关系映射,它会读取列表中的第一组元素产生数据映射,所以在数据为
1 | data = [ |
的时候,它就会要求其中输入的age栏都是string类型,当遇到'XiaoHong'的12.0时,便会出错退出.
知道了出错的原因那就好办了,只需要在读取excel表数据时将数据强转为对应于数据库表的类型就可以了,之后就可以用executemany()的方法进行处理数据了.
使用过程中可能会遇到的一些错误
ORA-00911: invalid character
出现这个问题很有可能是sql句末出现了分号;,在通过cx_Oracle对数据库进行操作时,所有的sql语句都不需要加最后的分号,去掉分号再尝试一遍即可.
ORA-00984: column not allowed here
这个问题就是因为插入的字符串没有加单引号,看看代码是否写成了类似于
sql = f""" insert into classroom values ({name}, {age},{sex})"""
的样子,出现这个原因大概率是因为使用了格式化字符串的方法来编写sql语句,所以这里还是再强调一遍推荐使用 绑定变量 的方法进行sql语句编写
程序执行完后数据并未写入数据库
目前没有遇到过如此问题,不过记得关闭连接之前先提交事务commit(),该问题很有可能是因为事务忘提交而导致的事务回滚造成的.